Coding Got Faster. Delivery Did Not.
AI made output cheaper to produce. It did not make engineering judgment easier to skip.
This post expands on a thread I posted on LinkedIn that got more traction than expected. The core argument is the same; the examples are new.
The headline is true
AI does make coding faster. That part is not hype — it is observable, measurable, and real. Boilerplate that once took an afternoon gets generated in minutes. Straightforward refactors, test scaffolding, first-pass implementations of well-defined tasks — all of it moves faster than it did two years ago.
This is genuinely useful. I am not arguing against it. Any engineer who has spent a morning writing repetitive CRUD code or constructing test fixtures from scratch knows the value of getting that work done quickly.
But faster coding was never the same thing as faster delivery. And the gap between the two has gotten wider, not narrower.
What faster coding actually changed
When coding gets faster, more pull requests get opened. That is the direct effect. The downstream effect — the one that does not show up in anyone's velocity metrics — is that review load goes up proportionally, and reviewer attention does not.
The math stops working. A team that could thoughtfully review twelve pull requests a week is now looking at twenty-five. The surface area is the same. The time is not. The default response shifts, almost invisibly, toward "this looks fine."
This is not a failure of individual reviewers. It is a system that was not designed for the new volume. And it is the kind of problem that does not announce itself. PRs keep getting merged. Velocity numbers look good. The cost accumulates quietly in the codebase.
Three things that got worse
I want to be specific here, because the abstract version of this argument is easy to dismiss. These are patterns I have seen directly, not hypothetical concerns.
Duplication and the inability to generalize. AI is very good at producing code that solves the problem in front of it. It is not good at recognizing that the problem in front of it was already solved somewhere else in the codebase, or that the right answer is a small abstraction that handles both cases. The result is duplication — not the obvious copy-paste kind that any linter would catch, but the subtler kind where two functions do nearly the same thing with slightly different signatures, written weeks apart, by different people who each asked the same question to the same tool and got slightly different answers. The codebase accumulates weight without anyone making a deliberate decision to add it.
The self-review that stopped happening. Before AI-assisted coding became common, engineers who submitted half-baked pull requests at least had to live with the code long enough to write it. There was some natural forcing function. Now the gap between "I have an idea" and "I have a PR open" is thirty minutes. The self-review — reading the diff before you push, noticing the edge case you did not handle, catching the naming that made sense when you wrote it but reads poorly in context — that step gets skipped more often.
And then, when a reviewer catches something, the dynamic that follows has changed too. The author feeds the comment back to the coding assistant. The assistant generates a fix. The author pastes it in and pushes. The reviewer's comment was answered. But the engineer never thought about why the reviewer raised it, whether the fix is actually right, or what the pattern means for the rest of the codebase. The feedback loop that used to build judgment has been short-circuited.
"I don't know, AI wrote it." This one started appearing in code reviews. Someone asks why a particular approach was chosen — why this data structure, why this boundary, why this abstraction. The answer, increasingly, is "I don't know, AI wrote it." Sometimes this is said defensively. Sometimes it is said completely matter-of-factly, as though it settles the question.
It does not settle the question. The author of a pull request is responsible for understanding the code they are submitting, regardless of what produced it. But the fact that this answer is now given — and given without embarrassment — is a signal about what has changed in how engineers relate to the code they ship.
The origin of code is not the same as the soundness of code
"AI wrote it" is a statement about origin. It tells you how the code was produced. It does not tell you whether the design is right, whether the abstraction is sound, whether the failure modes were considered, or whether the system is better for having the change.
This is exactly the same problem as "all tests passed." Tests passing is a statement about one class of checks. It tells you the code behaves correctly under the conditions the tests describe. It does not tell you the conditions are the right ones, that the coverage is complete, or that the behavior it is testing is the behavior you actually wanted.
Both statements are meaningful. Neither means what people want them to mean.
AI did not reduce the need for engineering judgment. It made bad judgment easier to scale.
A weak decision that once took a day to turn into code can now show up in an hour, get reviewed too quickly, merged too casually, and repeated across the codebase before anyone stops to ask whether it belonged there at all. The speed advantage is real. So is the compounding cost.
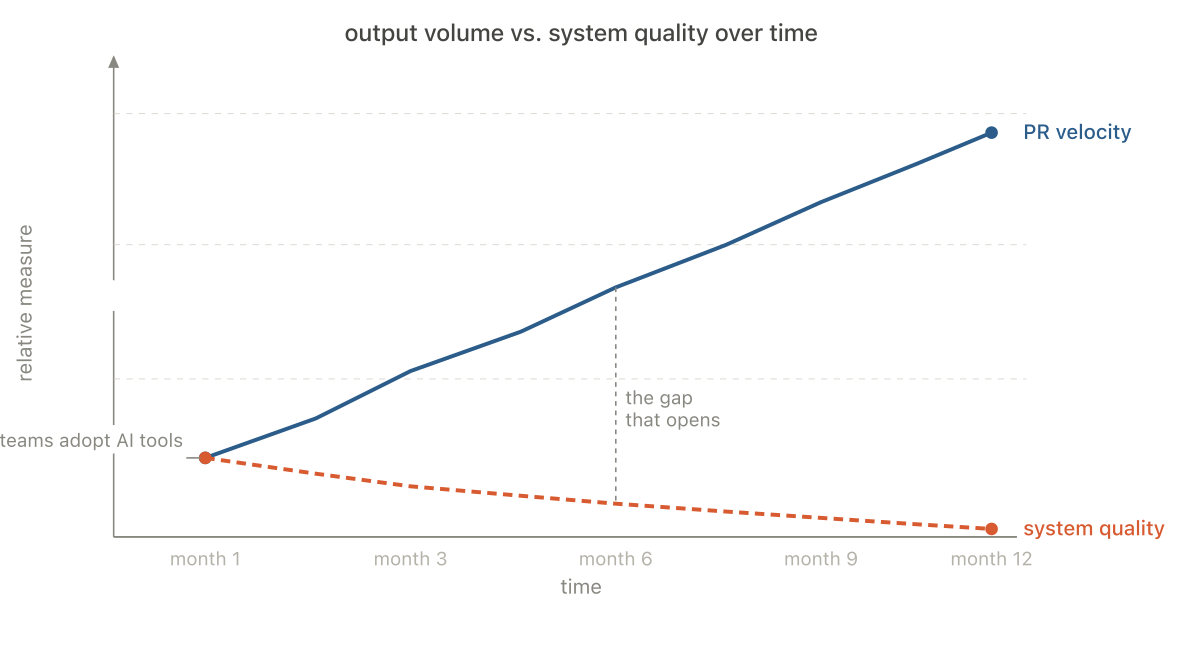
The gap that takes a while to see
For a while, a strong engineer with AI and a weak engineer with AI can look equally productive. Both are opening pull requests. Both are closing tickets. Both are shipping features. The difference is not visible in velocity metrics — it is visible in what the codebase looks like six months later.
The strong engineer uses the speed to do more thinking. The weak engineer uses the speed to do less. The strong engineer's PRs are faster to review because the design is clear. The weak engineer's PRs are faster to open because the design was outsourced. These are not the same thing, and for a while the metrics do not know the difference.
The difference shows up later — in review fatigue, in operational drag, in the inconsistent patterns that make onboarding harder, in the strange coupling that makes changes more expensive than they should be. In code that technically works but leaves the system worse than it was before.
That gap — between how productive a team looks and how well the system is actually doing — is the real management problem AI introduced. It did not go away when teams adopted AI tools. In most cases, it widened.
What to do about it is a different question. That is the subject of the next post.