Why I Built a Custom Voice Activity Detector in Java
Twilio streams continuous audio. Transcription APIs bill by the minute. The gap between a working prototype and production-grade speech detection is where the interesting engineering lives.
In late August 2024, I started building a conversational AI voice application — the kind where you call a phone number, an AI answers, and you have a back-and-forth conversation. The stack was Java, Spring Boot 3, and Twilio for the telephony layer.
The architecture seemed straightforward. Twilio streams audio from the caller over a WebSocket, my server processes it, sends it to a speech-to-text service for transcription, feeds the transcript to an LLM, converts the response to speech, and streams it back. A loop.
Except for one piece I had not figured out: how does the system know when the caller is done speaking?
The problem with continuous audio streams
Twilio does not send pre-segmented utterances. It sends a continuous stream of 8kHz mu-law encoded audio chunks over a WebSocket — about 20 milliseconds at a time, indefinitely. Silence, speech, background noise, the AI's own response playing through the caller's speaker — it all comes through as one undifferentiated river of bytes.
Without knowing where speech starts and ends, you cannot have a conversation. Send the audio to transcription too early and you cut the caller off mid-sentence. Wait too long and the interaction feels sluggish. Get it wrong consistently and the whole thing falls apart — the AI talks over people, responds to silence, or sits there waiting while the caller wonders if the line went dead.
I needed a voice activity detector. Something that could sit in the audio pipeline, listen to the stream in real time, and signal when speech starts and when it ends.
The cost of streaming everything
My first instinct was to let the transcription service handle it. Google Speech-to-Text, Deepgram, and OpenAI Whisper all offer streaming transcription with their own endpoint detection. They listen to the audio and decide when someone stops talking.
The issue is economics.
In a typical AI voice conversation, the caller does not speak for most of the call. The user asks a question — a few seconds. The system processes it — LLM latency. The AI responds — text-to-speech playback, which can run 10 to 30 seconds for a detailed answer. During that entire response, the audio stream is still flowing. It is just silence, or the AI's own voice bleeding through the caller's microphone.
In a 2.5-minute conversation I measured, the caller spoke for about 45 seconds total. The rest was system latency and AI responses. That is 30% speech, 70% billable silence.
If you stream all of that to a transcription API, you pay for 2.5 minutes. If you detect speech boundaries yourself and only send the actual speech, you pay for 45 seconds. A 70% cost reduction per call.
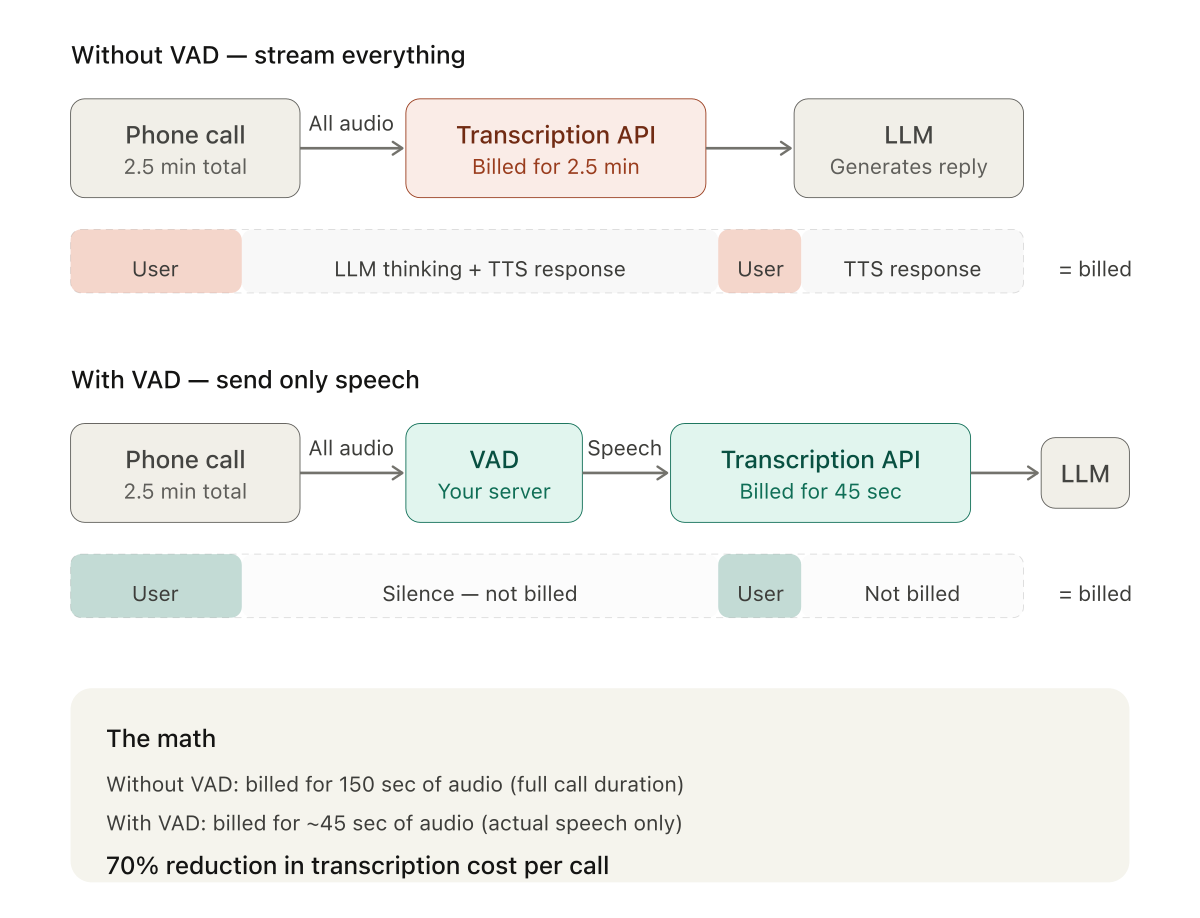
The math gets more dramatic as conversations get longer. In many use cases — appointment scheduling, order status checks, simple confirmations — the user might say nothing more than "yes," "Tuesday at 3," or "that's correct." Five seconds of speech in a two-minute call. You would be paying for 115 seconds of silence.
At scale, this is the difference between a viable product and one that bleeds money. A thousand 5-minute calls per month where the user speaks for 1.5 minutes each: without a VAD, you are billed for roughly 83 hours of audio. With a VAD, 25 hours. The per-minute rate — whether it is Google's $0.016, Deepgram's $0.0077, or Whisper's $0.006 — matters less than the minutes you do not send.
Scenario
Prices: Google STT standard $0.016/min, enhanced $0.024/min. Deepgram Nova-3 streaming $0.0077/min, pre-recorded $0.0043/min. OpenAI Whisper $0.006/min. Costs shown per call; at scale multiply by call volume.
The Java VAD landscape in 2024
With the motivation clear, I went looking for existing solutions. What I found was thin.
WebRTC VAD had Java ports, but they were wrappers around native code with JNI dependencies — not ideal for a clean Spring Boot deployment. Sphinx4, part of the CMU Sphinx speech recognition project, included VAD capabilities, but it was a full speech recognition framework. Pulling in the VAD meant pulling in everything else. TarsosDSP was a Java audio processing library with some relevant functionality, oriented more toward music analysis than real-time telephony speech detection.
None of them fit what was ultimately a well-scoped problem: take a stream of 8kHz telephone audio, figure out when someone is talking, and signal when they stop.
I prototyped a solution in Node.js first, using node-vad and a WebSocket server, to validate the concept. It worked. But my production stack was Java, and I did not want to introduce a Node.js sidecar service for a single function.
Building it through conversation
This was August through November 2024. Claude Code — Anthropic's agentic coding tool that can read your codebase, edit files, and run commands — did not exist yet. There were no AI tools that could look at my project, understand the context, and make changes directly.
The workflow was conversational. I would describe a problem, get code back, paste it into my IDE, run it, hit an issue, copy the error or the relevant code snippet, go back to the chat, and iterate. Every piece of context had to be manually shuttled between my editor and the conversation window. Every code suggestion had to be manually integrated.
The first version was a simple energy threshold detector. It measured the amplitude of each audio chunk and decided: above a threshold, someone is talking; below it, silence. It worked about 90% of the time.
The other 10% was the problem.
Keyboard clicks triggered voice detection. An elevator door opening in the background registered as speech. A car passing by outside was enough. The detector would capture a chunk of what was essentially noise, send it for transcription, and get back either nothing or garbage — which then confused the LLM. I spent more time debugging false positives than I had spent building the initial detector.
The gap between 90% accuracy and production-grade is where the interesting engineering lives. A single-metric energy detector gets you most of the way there. The rest requires understanding what makes human speech different from every other sound.
That failure — the gap between 90% and production-grade — turned out to be the interesting part. Solving it required moving from a single energy metric to a combination of features: zero-crossing rate to distinguish between speech and impulsive noise, spectral centroid to identify the frequency characteristics of human voice, pitch detection through autocorrelation to confirm that what the detector heard was actually voiced speech. Each feature was added because the previous version failed in a specific, identifiable way.
The auto-calibration system came from a related problem. A threshold that worked in a quiet office failed in a coffee shop. The detector needed to adapt to ambient noise levels on every call, not rely on hardcoded values. Running averages of energy, zero-crossing rate, and spectral centroid during an initial silence period gave the system a baseline to calibrate against — with margins tuned to separate speech from the ambient floor.
The constraint that helped
There is an unexpected benefit to building through a chat interface rather than an agentic tool. Because I had to articulate every problem precisely enough for the AI to help without seeing my codebase, I ended up with a clearer mental model of my own system than I might have otherwise.
Every conversation forced me to isolate the specific question: not "the audio sounds wrong" but "the mu-law decompression table produces values outside the expected range when the input byte has bit 7 set." The discipline of translating a vague sense that something is broken into a precise, self-contained question is valuable whether you are talking to an AI or to a colleague.
Over three months and several dozen conversations, the VAD went from a single-metric energy detector to a multi-feature system with adaptive calibration. The rest of this series walks through that progression — the audio format plumbing, the signal processing, the false positives and how each one was solved, the full pipeline integration in Spring Boot, and the client-side JavaScript work that made it all testable.
The next post covers the first layer of the problem: telephony audio formats. Mu-law encoding, PCM conversion, sample rate handling, and the surprising number of ways byte-to-float conversion can go silently wrong.