Taming Telephony Audio — Mu-law, PCM, and the Conversion Gauntlet
Before you can detect voice activity, you have to understand what you're looking at. What I thought was PCM was something else entirely.
Before I could detect voice activity, I had to understand what I was looking at. The audio coming from Twilio was not PCM. It was not a WAV file. It was a stream of 8-bit mu-law encoded bytes at 8000 Hz — a format designed for telephone networks in the 1970s, still the default for most telephony APIs in 2024.
I did not know any of this when I started. My first byteToFloat method treated the incoming bytes as 16-bit PCM, pairing adjacent bytes and dividing by 32768. The code compiled, produced float arrays, and returned plausible-looking numbers. It was wrong in a way that took time to surface.
What mu-law actually is
Mu-law is a companding algorithm. It compresses audio by applying a logarithmic function to the amplitude before encoding, which gives quiet sounds more resolution and loud sounds less. This matches human hearing perception — we are more sensitive to differences between quiet sounds than between loud ones. The result is that 16-bit dynamic range gets packed into 8 bits with subjectively acceptable quality for voice.
Interactive chart showing the mu-law compression curve compared to linear encoding
Mu-law compresses 16-bit dynamic range into 8 bits. Quiet sounds get more resolution, loud sounds get less — matching human hearing perception. The curve shows why a lookup table is the practical way to decode: the mapping is nonlinear but fixed.
The important detail for a developer: each byte is one sample. Not two bytes per sample, as with 16-bit PCM. One byte, one sample, 256 possible values. The mapping from byte value to amplitude is nonlinear and specified by a formula, but in practice everyone uses a 256-entry lookup table.
This is where my first implementation went wrong.
The silent bug
My original conversion method assumed 16-bit PCM:
// Wrong: treats mu-law bytes as 16-bit PCM pairs
float[] floatData = new float[byteData.length / 2];
for (int i = 0; i < floatData.length; i++) {
short sample = (short) (((byteData[i * 2 + 1] & 0xFF) << 8)
| (byteData[i * 2] & 0xFF));
floatData[i] = sample / 32768.0f;
}This code pairs every two adjacent bytes, interprets them as a 16-bit signed integer, and divides by 32768 to normalize. When the input is actually 16-bit PCM, this is correct. When the input is mu-law, two things go wrong simultaneously.
First, the sample count is halved. Eight thousand bytes per second of mu-law becomes four thousand floats instead of eight thousand. The audio plays at double speed if you try to use it, though I was not playing it back — I was feeding it to a VAD, which obscured the problem.
Second, the values are meaningless. Pairing two mu-law bytes and treating them as a 16-bit integer produces numbers that bear no relation to the original signal. The output is noise — but it is structured noise, not random, so it does not immediately look like garbage. Energy calculations produce results. Zero-crossing counts produce results. They are just wrong results.
I discovered the problem when I enabled mu-law to PCM conversion in the pipeline and the audio output — which had been clean — became noisy. Disabling the conversion eliminated the noise. The conversion itself was the source.
The correct conversion
The fix was a static lookup table, computed once at class initialization:
private static final float[] MU_LAW_DECOMPRESSION_TABLE = new float[256];
static {
for (int i = 0; i < 256; i++) {
int mu = ~i;
int t = ((mu & 0xf) << 3) + 0x84;
t = ((mu & 0x70) != 0 ? (t << ((mu & 0x70) >> 4)) : t >> 1);
MU_LAW_DECOMPRESSION_TABLE[i] =
(float) ((mu & 0x80) != 0 ? (0x84 - t) : (t - 0x84)) / 32768.0f;
}
}The table maps each of the 256 possible byte values to a float between -1.0 and 1.0. The bit manipulation looks opaque, but it implements the inverse of the mu-law encoding formula. The sign bit is extracted, the exponent and mantissa are unpacked, and the result is scaled to the standard audio float range.
With the table built, conversion is a single array index per sample:
public float[] byteToFloatArray(byte[] byteData) {
float[] floatData = new float[byteData.length]; // Not length / 2
for (int i = 0; i < byteData.length; i++) {
floatData[i] = MU_LAW_DECOMPRESSION_TABLE[byteData[i] & 0xFF];
// & 0xFF: converts signed Java byte (-128..127) to unsigned index (0..255)
}
return floatData;
}The & 0xFF mask converts the signed Java byte (-128 to 127) to an unsigned index (0 to 255). The output array is the same length as the input — one float per byte, not one float per two bytes.
Going the other direction
Converting from float back to mu-law is asymmetric in complexity. Decompression is a table lookup. Compression requires sign extraction, logarithmic scaling, bit packing, and edge-case handling. This matters on the client side — when testing, I needed to send audio files from a browser to the server in the same format Twilio would use.
The client-side JavaScript for this was more involved:
function pcm16ToMuLaw(pcm16) {
const mulaw = new Uint8Array(pcm16.length);
for (let i = 0; i < pcm16.length; i++) {
let sample = pcm16[i];
const sign = (sample >> 8) & 0x80;
if (sign != 0) sample = -sample;
sample = Math.min(sample, 32635);
let exponent = mulawTable[(sample >> 7) & 0xFF];
let mantissa = (sample >> (exponent + 3)) & 0x0F;
mulaw[i] = ~(sign | (exponent << 4) | mantissa) & 0xFF;
}
return mulaw;
}The asymmetry between encoding and decoding is a recurring pattern in audio codecs. It is also a practical hint about where to put the complexity boundary. The server — which needs to decode fast and often — gets a lookup table. The client — which encodes occasionally, for testing — gets the full algorithm.
Sample rate and the unnecessary resampler
Alongside the mu-law issue, I inherited a resampleWithSincInterpolation method in the codebase. It implemented sinc interpolation — the theoretically ideal resampling algorithm — and it was called on every audio chunk.
The input rate was 8000 Hz. The output rate was 8000 Hz.
When the ratio is 1:1, sinc interpolation degenerates into a weighted sum of neighboring samples that reproduces the original signal with rounding error. It is a computationally expensive no-op. The resampler was there because the code was originally written for a different sample rate configuration and never updated when the architecture settled on 8kHz end-to-end.
Sinc interpolation with a window of 10 samples in each direction means every output sample is a weighted average of 21 input samples. At 8000 Hz with 20ms chunks, that is 160 samples per chunk, each touching 21 neighbors. The computation is not trivial, and the result — when the rates match — is functionally identical to the input. Removing it eliminated unnecessary computation on every audio chunk and a potential source of subtle audio artifacts.
Duration calculations and byte arithmetic
A smaller but persistent source of confusion: calculating the duration of an audio chunk from its byte array length. The formula depends on the encoding:
For mu-law (8-bit, 1 byte per sample): duration_ms = (array.length / sampleRate) * 1000
For 16-bit PCM (2 bytes per sample): duration_ms = (array.length / 2 / sampleRate) * 1000
For float (4 bytes per sample): duration_ms = (array.length / 4 / sampleRate) * 1000
Getting this wrong does not produce an error. It produces a duration that is off by a factor of 2 or 4, which propagates into buffer size calculations, silence timeout logic, and calibration windows. If your VAD thinks 20ms of audio is actually 40ms, its silence timeout will trigger at half the intended delay.
The fix is straightforward once you know the encoding. The problem is knowing the encoding. In a pipeline that converts between formats — mu-law bytes in, float arrays to the VAD, 16-bit PCM bytes out to storage — it is easy to apply the wrong formula at the wrong stage. I kept the bytes-per-sample constant explicit at each conversion boundary rather than relying on context.
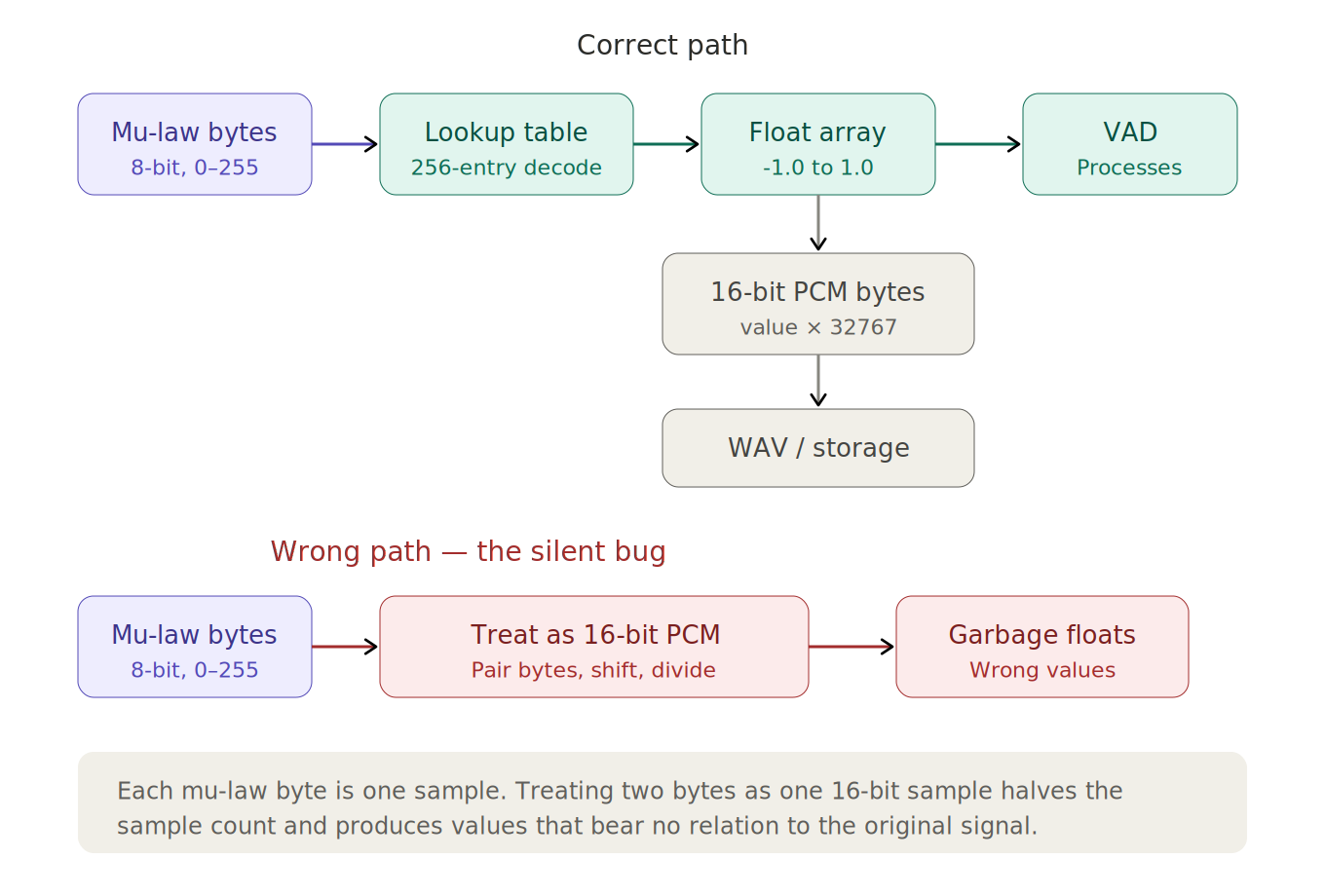
The conversion chain
The complete audio path in my system, from Twilio to the VAD, looks like this:
Twilio sends 8-bit mu-law bytes at 8kHz over a WebSocket. The server decodes each chunk through the lookup table to get float arrays in the -1.0 to 1.0 range. Those floats go to the VAD for analysis. When the VAD identifies a speech segment, the accumulated floats are converted to 16-bit PCM bytes (value * 32767, little-endian) and packaged for the transcription service.
Each stage has a specific bytes-per-sample ratio and a specific value range. Mu-law: 1 byte, 0–255. Float: 4 bytes, -1.0 to 1.0. PCM-16: 2 bytes, -32768 to 32767. Confusing any two of these produces output that looks structurally valid but is acoustically wrong.
None of this is conceptually difficult. It is plumbing — format conversion, byte manipulation, making sure the numbers at each stage mean what you think they mean. The difficulty is that mistakes are silent. The code runs. It produces arrays of numbers. Those numbers just do not represent the audio you intended.
The next post moves past the plumbing into the signal processing itself: measuring energy, zero-crossing rate, and spectral centroid, and discovering why a simple energy threshold gets you to 90% accuracy and no further.