LLMs as Reconciliation Engines, Not Parsers
The naive framing treats unstructured-to-structured conversion as a parsing problem. It fails the moment a canonical record already exists. Here's the mental model that actually holds.
Many useful systems have a structured record that needs to be updated from a less-structured input. A customer record updated from a sales email thread. A medical chart updated from a clinician's dictated note. A product catalog updated from a supplier's PDF spec sheet. A user profile updated from a resume.
The shape of the problem is the same in every case. One side is canonical — typed, validated, referenced by stable IDs, holding fields the other side does not mention. The other side is semi-structured — organized by convention but delivered as text, with typos, omissions, and ambiguity. The job is to get from one to the other without losing anything that matters.
The obvious framing is that this is a parsing problem. The LLM reads the messy input, produces a structured object, and the structured object replaces the record. I used this framing the first time I built one of these systems. It was wrong, and it took a few iterations to see why.
The rest of this post uses resume-to-profile reconciliation as the worked example, because that is the system I built. The argument generalizes to any of the cases above.
The naive framing
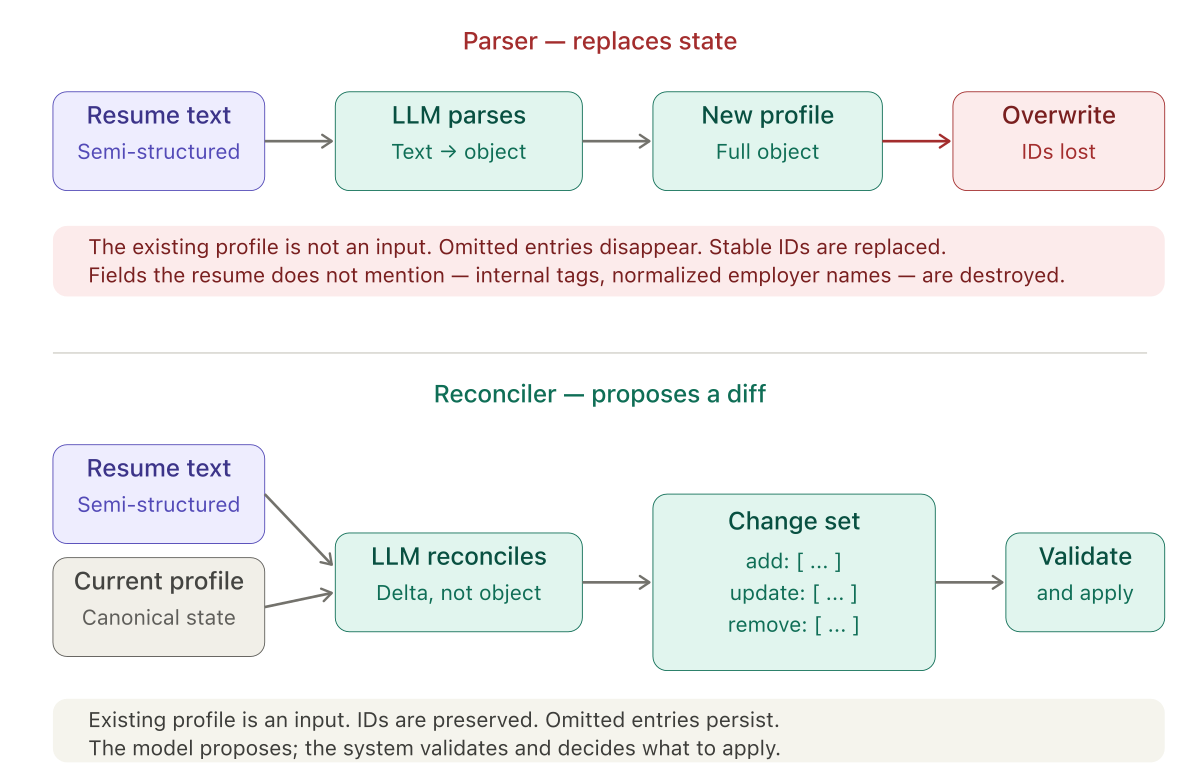
A resume is a blob of text with implicit structure. A profile is a typed record with stable IDs, enumerated fields, and validation rules. The obvious thing to do is parse the resume into the profile schema and write the result.
This approach has one property that makes it immediately appealing and eventually unusable: it is stateless. The LLM looks at the input, produces an object, and hands it over. Whatever was in the record before is irrelevant.
In practice, something was in the record before. The user had jobs, education entries, and certifications with IDs that other parts of the system reference. They had fields the resume does not mention — internal tags, derived codes, normalized employer names. They had older entries that the resume omits because the user chose not to include them on this version of the resume, not because they did not happen.
A parser-based approach either destroys all of that or preserves none of it. Neither is what the user wants. Swap "resume" for "dictated note" and "profile" for "medical chart," and every sentence above stays true.
The real job is reconciliation
The existing record is the canonical state. The new input is a proposed update to that state, delivered in an inconvenient format. What the LLM needs to produce is not a new record — it is a change set. A diff. A list of adds, updates, and removals that can be reviewed, validated, and applied transactionally.
This reframing changes almost every design decision that follows.
The output contract becomes a list of operations, not an object. The prompt asks for "jobs to add or update" and "jobs to remove" as separate lists. Each item references an existing ID when it applies to an existing entry, and omits an ID when it is new. The model is not producing the next version of the truth — it is proposing mutations to the current version.
Referential integrity becomes a first-class concern. Record IDs are opaque strings that must survive a round trip through a model that loves to clean up strings. Every prompt I write now has a variation of the same paragraph: IDs are randomly generated, every character is significant, do not modify them in any way. This reads as paranoid until you see what happens without it.
Conservative defaults become explicit rules. If an older entry is in the record but not in the input, the parser would drop it. The reconciler has to be told, in plain language, that absence from the input is not evidence the entry did not happen. The source document is curated. The canonical record is comprehensive. The rules reflect that asymmetry.
The model needs an escape hatch. Sometimes the record and the input appear to describe different entities — wrong file uploaded, account mix-up, corrupted data. A parser would merge them anyway and produce nonsense. A reconciler needs to be able to refuse, and explain why: "Do not generate a change set; provide a reason." This single rule has saved me from a category of silent data corruption I would not have anticipated.
The generalization within the system
Once the system is structured around change sets, something interesting happens. The input does not have to be a resume.
I started with resume reconciliation. Then I needed to support users who do not have a resume — they build or update their profile conversationally. The conversational flow produces its own structured input: a list of jobs the user wants to add or update, a list they want to remove, the same for education and certifications. It already looks like a change set.
But it is not applied to the profile directly. It still goes through the same reconciliation layer — because the LLM is the one that checks for duplicates against what is already in the profile, preserves IDs on updates, validates enum values, and catches conflicts. The input shape is different. The invariants are identical.
The LLM is not reconciling structured against unstructured. It is reconciling a proposed delta against an existing canonical state. The proposed delta can arrive as a PDF, as a form submission, as a chat transcript, as another system's export. The reconciler does not care.
The same prompt, with a different preamble describing the input medium, handles all of them. That is the payoff of the reframing.
The prompt as a specification
In a parser-based mental model, the prompt is an instruction: "read this and produce that." In a reconciler-based mental model, the prompt is closer to a specification. It enumerates invariants the output must satisfy:
- Preserve existing IDs exactly as given.
- Use only values from this controlled vocabulary.
- Do not remove entries based on absence; only on conflict.
- Prefer the more recent source for conflicting details.
- Refuse if the two sides cannot plausibly belong to the same entity.
Every one of these rules came from a specific failure. The model inventing a new enum value. The model dropping an entry because it was not in the input. The model modifying an ID by a single character and breaking foreign key references. Each rule encodes a hard-won constraint.
Written this way, the prompt starts to look less like a chat message and more like the kind of document an engineer writes when specifying a system with strict invariants. That is, I think, what it actually is.
Where LLMs belong on the contract
LLMs are good at producing diffs. They are less good at being trusted as the final writer of canonical state. Treating them as reconcilers, not parsers, puts them on the side of the contract where they do their best work — understanding the intent behind a messy input, and proposing changes to a system that still owns the truth.
The validation, the application of changes, the guarantees about referential integrity — those stay in code. The code does not have to be clever. It has to be strict. The LLM brings the understanding; the system brings the constraints.
The next post covers the specific failure modes I hit while building this, and the prompt patterns that fixed them — the temporal prior, enum discipline, ID preservation, conservative deletion, and the identity-mismatch escape hatch.