Hard Corners of LLM Reconciliation
Six specific ways a production LLM reconciler gets it wrong — and the prompt patterns that fixed each one. Everything here came from a ticket, a user report, or a suspicious log entry.
The reconciliation framing is only useful if it survives contact with actual failure modes. Because this system touches user profile data, we ran structured internal testing passes before any real traffic hit it — analyzing change sets in bulk, scoring output quality, and refusing to apply reconciliations that fell below a confidence threshold. Most of what is below was caught that way: either a low quality score that flagged a change set for review, or a pattern that appeared repeatedly in the validation output.
Each section describes the failure, shows the prompt change that fixed it, and explains why the fix works. Together they reveal a pattern: every failure was domain knowledge I had but had not written down. Every fix is the same knowledge, translated into language specific enough that the model cannot ignore it.
The temporal prior
An LLM trained on data through some cutoff date has a silent prior about what year it is. When the prior disagrees with the input, the model reconciles the disagreement by trusting the prior.
The first time I saw this, a user's resume listed a job with an end date of April 2024. The change set came back with the job marked for removal, with a reason stating that the end date was in the future and therefore invalid. The resume was correct. The model was confident the current year was earlier than it actually was.
The fix is mechanical. Inject the current date into the system prompt at request time.
The current date is December 2024. Use this as the reference for evaluating
whether dates in the resume are in the past, present, or future.That single line eliminated the class of bug. The model no longer needs to guess what year it is — it is told. I would not have written it without first seeing the failure. The instinct to include current date in the prompt does not exist until the model has confidently informed you that 2024 is in the future.
There is a second-order version of this problem. The model is also opinionated about plausible ranges for career durations, ages, and dates of education. The prompt has to give the model permission to flag implausibilities without over-correcting them — flagging is a signal for review, not a reason to delete.
Obvious typos and the correction budget
Resumes have typos. A start year of 2072 when context makes clear it should be 2022. A degree date that is ten years off from the surrounding entries. I want the model to fix these. I do not want it to invent corrections where the data is ambiguous.
The distinction is what I call a correction budget. The model is allowed to correct when the error is internally contradicted by the same document, and not allowed to correct when the correction requires outside knowledge.
If a date in the resume is clearly inconsistent with the surrounding context —
for example, a single-digit typo where the corrected date fits the timeline —
use the corrected value and note the correction in the reason field. Do not
correct values based on assumptions that are not supported by the surrounding
document.The "note the correction in the reason field" part matters. Every corrected value carries its justification into the change set, so a reviewer can audit the model's judgment rather than trust it silently. This is a general pattern: when the model is empowered to do something that could be wrong, require it to show its reasoning in a field that the application can surface.
Enum discipline
Profile fields with controlled vocabularies are the most reliable source of LLM drift. Degree level is the canonical example. The profile schema defines a specific list — BACHELORS, MASTERS, ASSOCIATES, DOCTORATE, HIGH_SCHOOL, and so on. The model, left to its own judgment, produces values like INCOMPLETE_BACHELORS or PARTIAL_MASTERS because those values feel logical given the input.
The fix has three parts, applied together. First, pass the valid values into the prompt at render time — inline with the task, not buried in the system instructions:
Valid degree levels (STRICTLY limited to these exact values, no variations allowed):
BACHELORS, MASTERS, ASSOCIATES, DOCTORATE, HIGH_SCHOOL, CERTIFICATE, UNKNOWNSecond, forbid inference explicitly. The model's default behavior is to be helpful by extending the taxonomy. You have to tell it not to:
Do not create or infer new degree levels, even if they seem logical.
If a degree does not exactly match one of the valid values, use UNKNOWN.Third, handle the specific cases that generate the most common invalid values. Incomplete degrees are the frequent culprit. The prompt spells out what to do for each kind of incompleteness.
This layered defense is ugly to read but effective. Each piece addresses a specific failure mode. Removing any of them brings the failures back.
A JSON schema with an enum constraint is a structural alternative for this specific case — the model physically cannot emit a value outside the allowed set. If your output format is schema-validated already, lean on the schema for vocabulary enforcement rather than prompt instructions. The constraint becomes structural rather than instructional. For the other failure modes in this post, there is no schema equivalent — the domain knowledge has to live in the prompt.
Preserving opaque identifiers
Profile IDs in my system are randomly generated strings. They have no semantic content. They are referenced by foreign keys in other tables. Losing or modifying a single character breaks references.
The model, by default, treats these strings as text that might benefit from cleanup. I have seen it lowercase them, strip what it thinks are extra characters, normalize separators, and truncate. Every one of these is catastrophic.
The prompt section that addresses this reads more like a legal clause than an instruction:
Profile keys, job IDs, education IDs, and certification IDs in the profile
are randomly generated strings that must be preserved exactly as is, with no
character additions, removals, or modifications of any kind. Each character
in these keys is significant and must remain in its original position.The repetition is deliberate. A terser version — "preserve IDs exactly" — is not sufficient. The model needs the specific injunctions against the specific transformations it would otherwise apply.
There is a defensive layer on top of this. The code that receives the change set verifies that every ID referenced in an update or remove operation exists in the current profile. If it does not, the operation is rejected and logged. The model is instructed correctly, but the system does not trust the instruction to hold.
Conservative deletion
The single most damaging failure mode I encountered was unwanted deletion. A user has a ten-year-old certification on their profile. They upload a resume focused on their current role that does not mention the old certification. The model, reasoning about reconciliation, concludes the certification should be removed.
The logic is not wrong. The reconciliation is supposed to make the profile match the resume. If the resume does not contain the certification, the profile should not contain it either. But this is the wrong framing.
Resumes are curated. Profiles are comprehensive. A resume omits things for rhetorical reasons. A profile holds everything that might matter. The prompt has to make this asymmetry explicit:
If a profile entry is not present in the resume:
* Do not remove it based on absence alone.
* Only remove if the resume contains information that directly contradicts
the entry, such as a conflicting timeline that makes the entry impossible.
* Older certifications and jobs may be intentionally omitted from a resume;
treat omission as silence, not as a signal to delete.The rule treats absence and contradiction as different kinds of evidence. Absence is silence. Contradiction is a signal. The model is allowed to act on signals and required to ignore silence.
The default has to be conservative. The cost of deleting something the user wanted to keep is much higher than the cost of leaving something stale.
The identity mismatch escape hatch
Sometimes the resume and the profile do not belong to the same person. The user uploaded the wrong file. A support agent attached a resume to the wrong account. Two people share a common name and the career histories are entirely different.
A parser-based system would produce a change set that reads as a total rewrite of the profile. The system would apply it. The user's real data would be replaced with someone else's.
The defense is to give the model permission to refuse:
If the resume and the profile are drastically different or do not appear to
belong to the same person, do not provide any changes. Instead, provide a
reason explaining why the resume cannot be reconciled into the profile.This rule changes the output contract. The change set schema needs an optional reason-for-refusal field. The application has to handle the empty-change-set case as a signal to stop, not as a success. The UI has to present the reason to the user so they can correct the underlying mistake.
In sampling, the model catches identity mismatches reliably when the mismatch is large. It does not catch them when the two careers are plausibly similar — a risk I accept because the alternative, manual review of every change set, is not viable at scale.
Deduplication as a first-class concern
The conversational flow introduced a failure mode the resume flow did not have. Users re-add jobs they already have. They mean to update an existing entry and create a duplicate instead. They paste the same certification twice. Any system that accepts user-generated changes to a profile has to deduplicate as part of the reconciliation.
Before generating add operations, check the existing profile for entries that
match the proposed addition by a combination of title/name, employer/issuer,
and date range. If a match is found, generate an update operation against
the existing entry instead of an add operation. If the existing profile
contains multiple entries that are duplicates of each other, keep the most
detailed entry and generate remove operations for the others with a reason
indicating that they are duplicates.Two things to notice. The match is on a combination of fields, not exact equality, because users will re-type "Google" as "Google Inc." and expect the system to recognize them as the same. The duplicate-removal rule is symmetric — the model cleans up pre-existing duplicates in the profile, not only duplicates introduced by the current change set. This turns each reconciliation pass into an opportunity to improve data quality.
The validation layer the prompt cannot replace
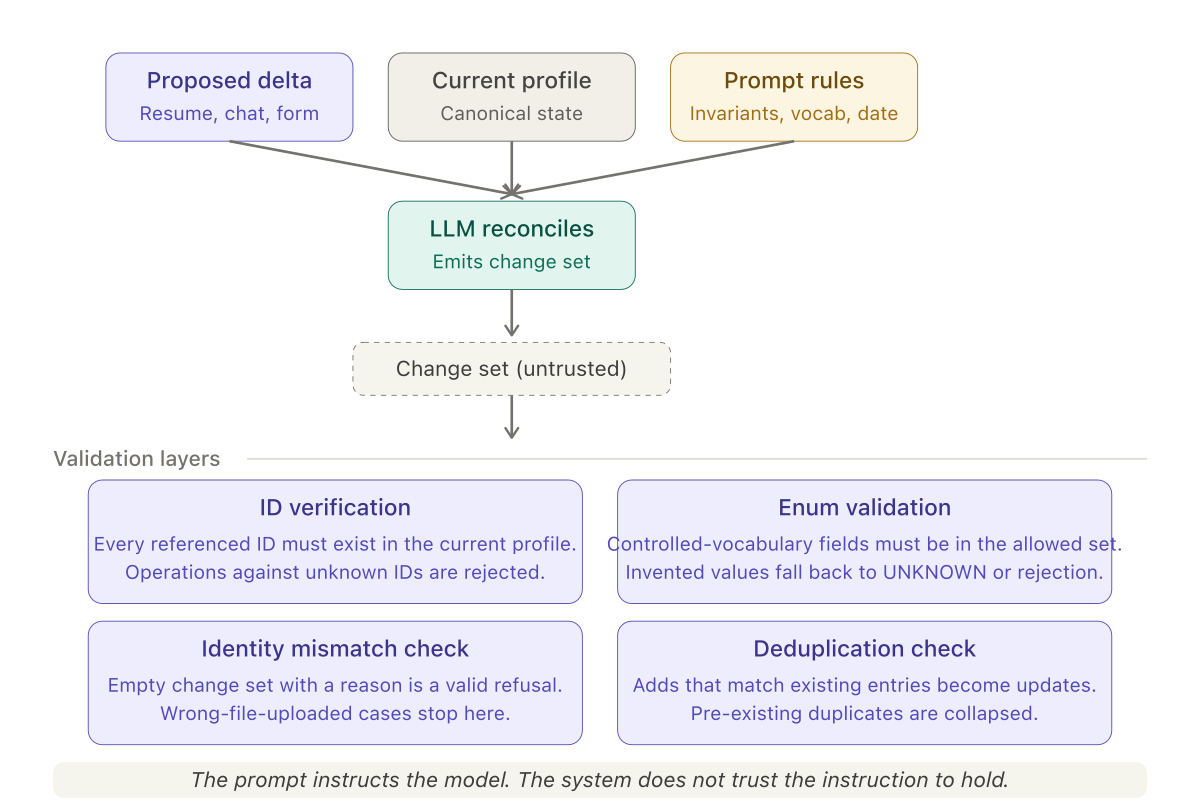
Every prompt rule above has a corresponding code-level check that runs after the model responds. ID verification confirms that every referenced ID exists in the current profile. Enum validation checks that all controlled-vocabulary fields contain allowed values. The identity mismatch check treats an empty change set as a structured signal, not an error. The deduplication check rejects add operations that would create duplicates the model missed.
The model is instructed correctly. The system does not trust the instruction to hold. These are not redundant — they are defense in depth. The prompt reduces the failure rate; the validation layer bounds the damage when failures occur anyway.
The meta-pattern
Looking at these rules together, a pattern emerges. Each one encodes a piece of domain knowledge that the model does not have and will not derive. The model knows what a resume looks like. It does not know that certifications are routinely omitted from resumes but should persist in profiles. The model knows how to parse dates. It does not know what year it is unless you tell it. The model knows what a degree is. It does not know which specific degree strings your schema accepts.
The prompt is the place where domain knowledge meets model capability. Every failure in this post started as domain knowledge I had but had not written down. Every fix is the same knowledge, translated into language specific enough that the model cannot ignore it.
The implementation effort on a system like this is not in the code that calls the LLM. The code is a few hundred lines at most. The effort is in discovering, articulating, and maintaining the specification of invariants that the prompt encodes. That specification is the actual artifact. The model is the interpreter.
This concludes the two-part series on LLM reconciliation. Part 1 covers the conceptual framing — why reconciliation is the right mental model and how the output schema reflects it. This post covers the specific failure modes and the fixes that held in production.