Repository Memory Makes AI More Useful — and More Dangerous
A repo-aware agent produces changes that look team-native. The problem is that "looks team-native" is not the same thing as "is correct."
This is the third post in a series on what AI is actually changing in software engineering and engineering management. The first post covers what happened to delivery when coding got faster. The second post covers how to think about where AI needs friction and where it does not. This one is about a more specific risk that is starting to show up as AI tooling gets more context-aware.
This post expands on a thread I posted on LinkedIn.
What changed — and why it matters
A stateless coding assistant gives generic help. It knows the language, knows common patterns, and can produce reasonable code for well-specified problems. What it cannot do is produce changes that feel like they belong in your codebase specifically — that match your naming conventions, your error handling patterns, your preferred way of structuring a service layer.
That is changing. AI tools are starting to remember your repository. Instruction files, persistent agent context, repo-level guidance, longer-running task ownership — all of it is heading in the same direction: not just helping with one file, but learning how your codebase tends to work.
The upside is real. Less repeated prompting. Better adherence to local conventions. Pull requests that do not need to be entirely reworked because the assistant ignored how the system actually handles errors or structures its modules. A contributor that gets more useful the longer it works with the codebase.
The risk is the flip side of the same property. Memory does not only preserve good judgment.
The plausibility problem
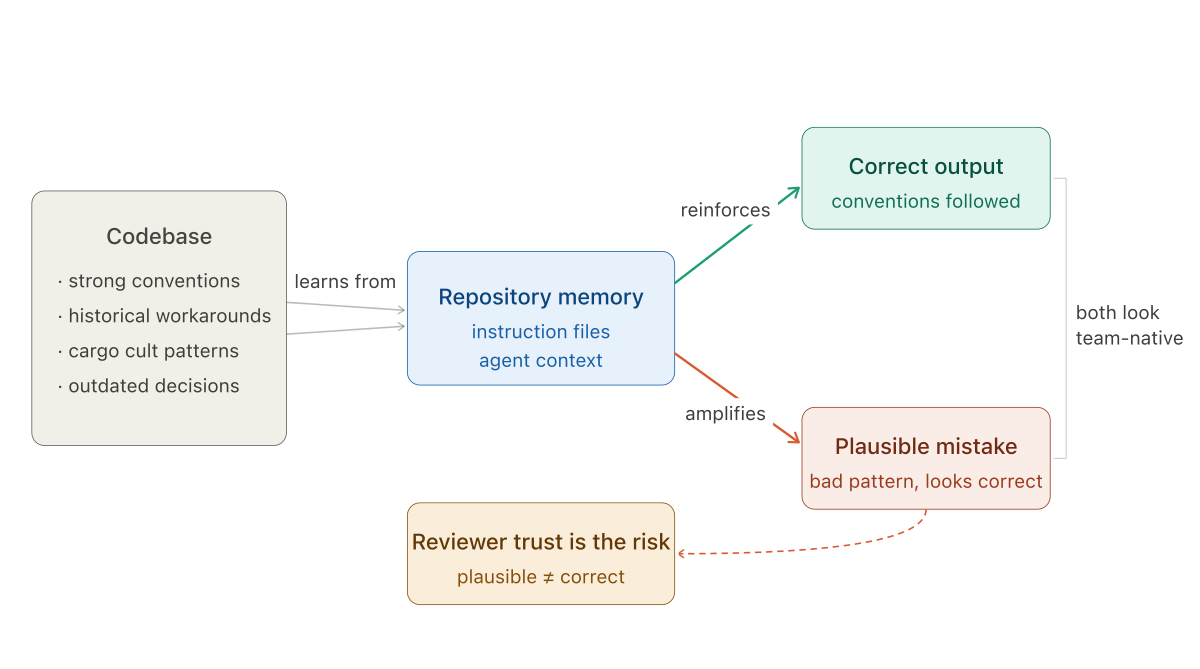
A repo-aware agent can make stronger contributions. It can also make more plausible mistakes. And plausible mistakes are harder to catch than generic ones.
When a stateless assistant writes something that does not belong, it usually looks wrong. The naming is off. The structure does not match. The reviewer notices it does not look like something the team would have written, and the question gets raised.
When a repo-aware agent writes something that does not belong, it often looks right. The naming fits. The tests follow local patterns. The structure matches what is already there. The pull request feels easier to trust because it looks like something the team would have written.
That is exactly where the risk goes up.
The issue is not that the model knows too little about your codebase. It is that it may know just enough to repeat bad local patterns more confidently.
How the cargo cult gets promoted
Every codebase accumulates decisions that made sense at the time and have not been revisited since. A temporary workaround that never got cleaned up. An abstraction that made sense for a problem that no longer exists. A service boundary that was drawn the way it was because of an organizational constraint, not a technical one. A pattern that was copy-pasted from an external tutorial in 2019 and propagated through fifteen modules before anyone noticed it was wrong for this context.
Normally these things are stable but inert. They sit in the codebase, occasionally inconvenient, not actively harmful.
Repository memory changes that dynamic. An agent that learns from the existing codebase will learn these patterns along with the good ones. It will reproduce them in new code with the same fluency it uses to reproduce the conventions that are actually correct. The pull request looks consistent with the rest of the codebase — because it is consistent. That is the problem.
A brittle abstraction starts to look like team convention. A temporary workaround starts to look like architecture. A cargo cult gets promoted into policy because the agent keeps reproducing it cleanly, reviewers keep approving it because it matches what is already there, and eventually the pattern is so widely replicated that changing it would be a large refactor.
The team is no longer reviewing code. It is quietly approving the repository's accumulated habits as if they were deliberate design decisions.
Instruction files are engineering artifacts now
The response to this is not to avoid repository memory. The benefits are real enough that the direction is settled. The response is to be deliberate about what the agent is allowed to learn from, and to treat the configuration of that memory as part of the engineering system rather than a personal productivity shortcut.
Instruction files, agent memory, repo-level hooks, and persistent guidance files should not be treated as individual configuration. They are becoming part of how the codebase is maintained. That means they need the same treatment as other engineering artifacts: ownership, review, and regular pruning.
If a repo-level instruction tells the agent how to structure service boundaries, that file should be reviewed with the same seriousness as the code it helps generate. If it encodes a pattern that was correct six months ago and is now wrong, updating that instruction is an engineering task — not a productivity setting to be changed informally by whoever set it up.
The more your AI knows about your repo, the more carefully you need to decide what it is allowed to learn from it.
Pruning matters as much as populating. An instruction file that has not been reviewed in a year is not neutral. It is actively encoding whatever state the codebase was in when it was written, and directing the agent to reproduce that state in new code.
The management angle
This is where the practical question lands: who owns the repository memory configuration, and what does "owning" it mean?
In most teams right now, the answer is unclear. Individual engineers set up instruction files to improve their own workflows. Nobody is looking at those files across the team to check for consistency, accuracy, or whether they are encoding patterns that should be retired.
That works fine when the tooling is stateless or nearly so. It stops working when the tooling is actively learning from and propagating what is in those files.
Repository memory configuration is worth treating as a first-class engineering concern. Not a heavy process — just explicit ownership, periodic review, and the same quality bar applied to the instructions as to the code they shape. If the instruction is wrong, the code it generates will be wrong in ways that look correct. That is a harder problem to fix than a failed test.
The next post in the series looks at how this connects to a broader shift in what code review actually means when the contributor is a system rather than a person — and what that requires from reviewers who were trained to evaluate human output.